
What is Common Crawl?
Common Crawl is a non-profit organization that crawls the web and freely provides its archives and datasets to the public. The organization was founded in 2007.
The Common Crawl corpus is a petabyte-scale archive of web pages and metadata. The dataset is hosted on Amazon Web Services (AWS) and is freely accessible to the public. The web pages in the dataset are continuously updated and are made available for download on a regular basis.
It’s the perfect tools to build a dataset for your AI project.
The dataset
The dataset is stored in Amazon S3. You can access the dataset using S3 API or by plain HTTP. S3 access is more optimized and recommended.
The dataset is split into multiple files. Each file is a part of the dataset and contains a subset of the web pages.
How to access the dataset
First go to https://commoncrawl.org/get-started
And select the last dataset available:
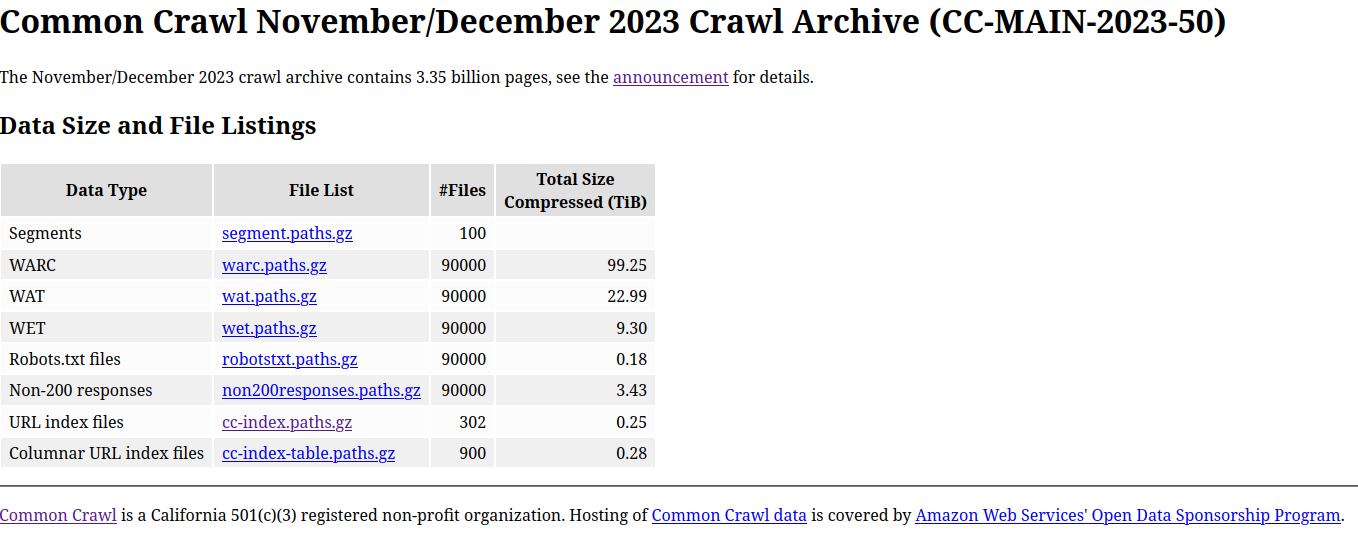
You can download the whole dataset but it’s unlikely that you have the storage to store it. But you don’t need to download the whole dataset if you are interested in a specific part of the dataset. You can download only the pages that you need.
To extract a page from the dataset you need:
- The segment file of the page
- The offset of the page in the segment file
- The length of the page in the segment file
This information is stored in the index of the dataset. The index is a file that contains the location of each URL in the dataset.
Once you have this information, you can perform an HTTP range request to download the page.
import gzip
import io
import requests
segment_file = 'crawl-data/CC-MAIN-2023-50/segments/1700679100499.43/warc/CC-MAIN-20231203094028-20231203124028-00893.warc.gz'
offset = 225013702
length = 7069
url = f'https://data.commoncrawl.org/{segment_file}'
response = requests.get(URL, headers={'Range': f'bytes={offset}-{offset+length-1}'})
if response.status_code == 206:
content = response.content
# Decompress the data
with gzip.open(io.BytesIO(content), 'rb') as f:
content = f.read()
print(content)
else:
print(f"Failed to fetch data: {response.status_code}")
How to get the location of a page in the dataset
Use the Common Crawl Index API
The Common Crawl Index API is a service that provides a simple interface to search the Common Crawl corpus. The API allows you to search for web pages that match a specific query.
The API is very simple you just pass the URL of the page that you are looking for and the API will return the location of the page in the dataset.
For example, for the page https://commoncrawl.org/faq you can use the following request:
http://index.commoncrawl.org/CC-MAIN-2023-50-index?url=commoncrawl.org%2Ffaq&output=json
You can replace CC-MAIN-2023-50 by the last dataset available.
{"urlkey": "org,commoncrawl)/faq", "timestamp": "20231203094453", "url": "https://commoncrawl.org/faq", "mime": "text/html", "mime-detected": "text/html", "status": "200", "digest": "E6N62SALJEROKFK4BVRK523WLDBV67RW", "length": "7069", "offset": "225013702", "filename": "crawl-data/CC-MAIN-2023-50/segments/1700679100499.43/warc/CC-MAIN-20231203094028-20231203124028-00893.warc.gz", "languages": "eng", "encoding": "UTF-8"}
The Common Crawl foundation provides a full example on how to use the API and retrieve the page: https://gist.github.com/thunderpoot/58a748565d2e5b2582520fa535821908#file-cc_fetch_page-py
This method is the easiest way to get the location of a specific page in the dataset but if you need to get the location of a lot of pages it’s not the best way to do it.
Use the index files
You can download all the index files from the dataset and search the location of the page in the files.
The file cc-index.paths.gz contains the location of all the index files. You can download this file and extract the location of the index files. The whole index size is around 300GB compressed.
Other versions of the index file cc-index-table.paths.gz is available. This is the same data but as Apache Parquet files. This format can be read by tools like DuckDB, Apache Spark, Trino… The usage will be similar to the usage of the AWS Athena.
Use AWS Athena
Athena is a Trino-based serverless interactive query service that makes it easy to analyze large amounts of data in Amazon S3 using standard SQL.
Athena is cost-effective and easy to use. There is no need to set up or manage infrastructure, and you only pay for the queries that you run.
You pay 5$ by TB scanned. If you correctly use the partitioning of the dataset the cost can be very low.
Setup Athena
You need to select the region US-East-1 (N. Virginia) to access the common crawl dataset.
Open the query editor and create a new database:
CREATE DATABASE ccindex
Next you need to create a table by running the following query: https://github.com/commoncrawl/cc-index-table/blob/main/src/sql/athena/cc-index-create-table-flat.sql
CREATE EXTERNAL TABLE IF NOT EXISTS ccindex (
url_surtkey STRING,
URL STRING,
url_host_name STRING,
url_host_tld STRING,
url_host_2nd_last_part STRING,
url_host_3rd_last_part STRING,
url_host_4th_last_part STRING,
url_host_5th_last_part STRING,
url_host_registry_suffix STRING,
url_host_registered_domain STRING,
url_host_private_suffix STRING,
url_host_private_domain STRING,
url_host_name_reversed STRING,
url_protocol STRING,
url_port INT,
url_path STRING,
url_query STRING,
fetch_time TIMESTAMP,
fetch_status SMALLINT,
fetch_redirect STRING,
content_digest STRING,
content_mime_type STRING,
content_mime_detected STRING,
content_charset STRING,
content_languages STRING,
content_truncated STRING,
warc_filename STRING,
warc_record_offset INT,
warc_record_length INT,
warc_segment STRING)
PARTITIONED BY (
crawl STRING,
subset STRING)
STORED AS parquet
LOCATION 's3://commoncrawl/cc-index/table/cc-main/warc/';
The table is not created but if you try a query it’s not going to work.
You need first to repair the table:
MSCK REPAIR TABLE ccindex
You will also need to do that when a new dataset is available.
Run a query
First you can try that the dataset is correctly loaded by running the following query:
SELECT * FROM ccindex LIMIT 1
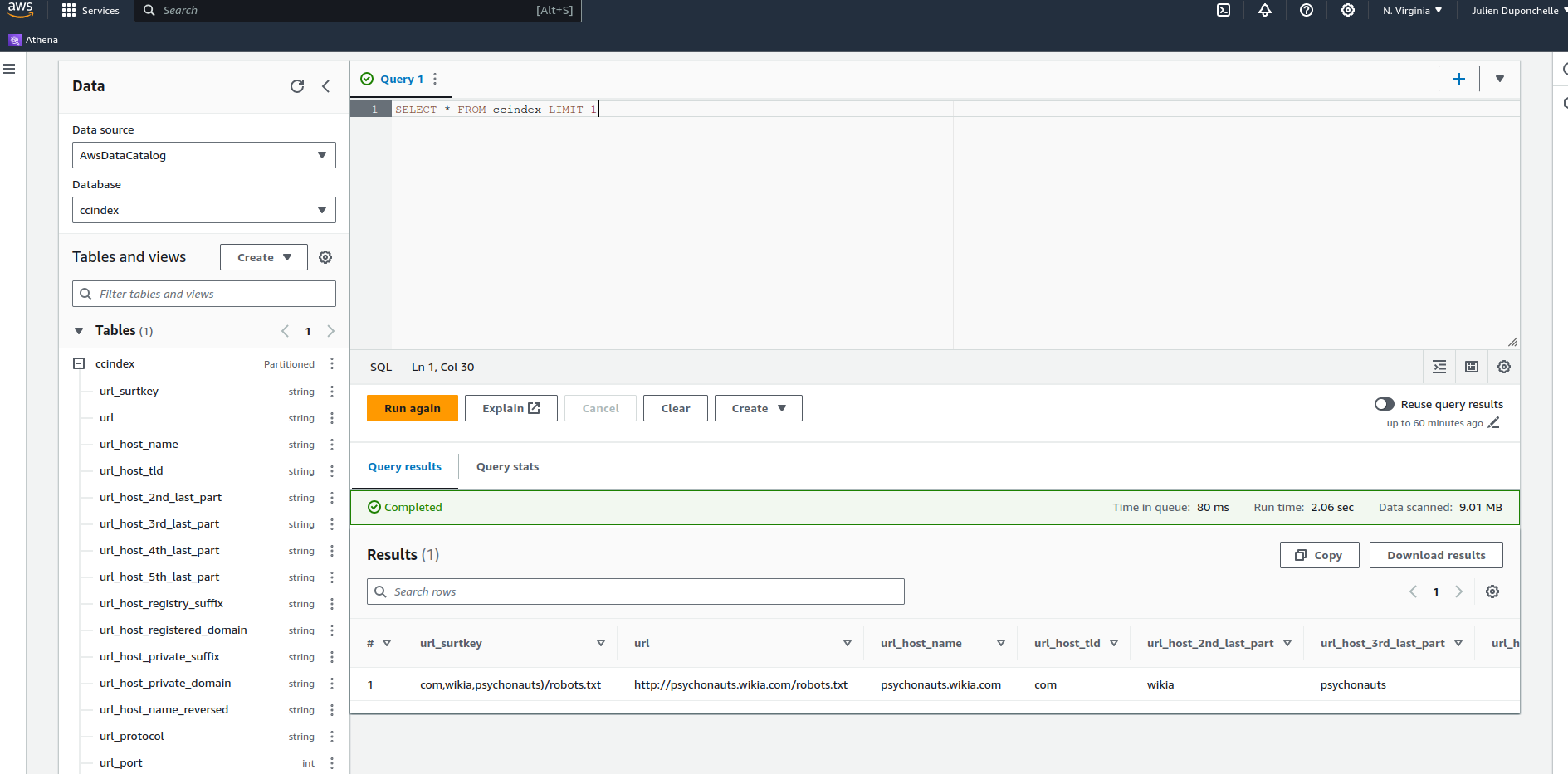
When you do a query make sure to pay attention to the cost of the query.
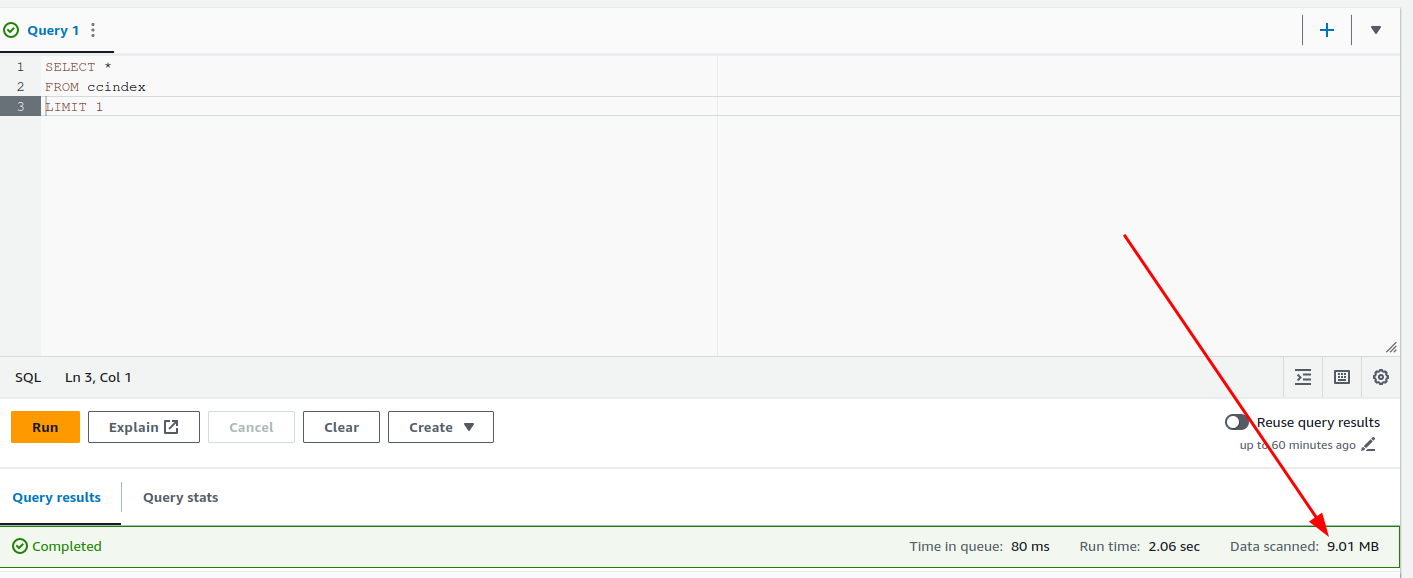
To reduce the cost makes sure to use the crawl and subset columns in your query. This will reduce the amount of data scanned because the dataset is partitioned by crawl and subset.
Also use LIMIT to reduce the amount of data returned by the query.
This request will return to the location of all the pages of the website trino.io:
SELECT URL,
warc_filename,
warc_record_offset,
warc_record_length
FROM ccindex
WHERE crawl = 'CC-MAIN-2023-50'
AND subset = 'warc'
AND url_host_name = 'trino.io'
AND content_mime_type = 'text/html'
LIMIT 1000
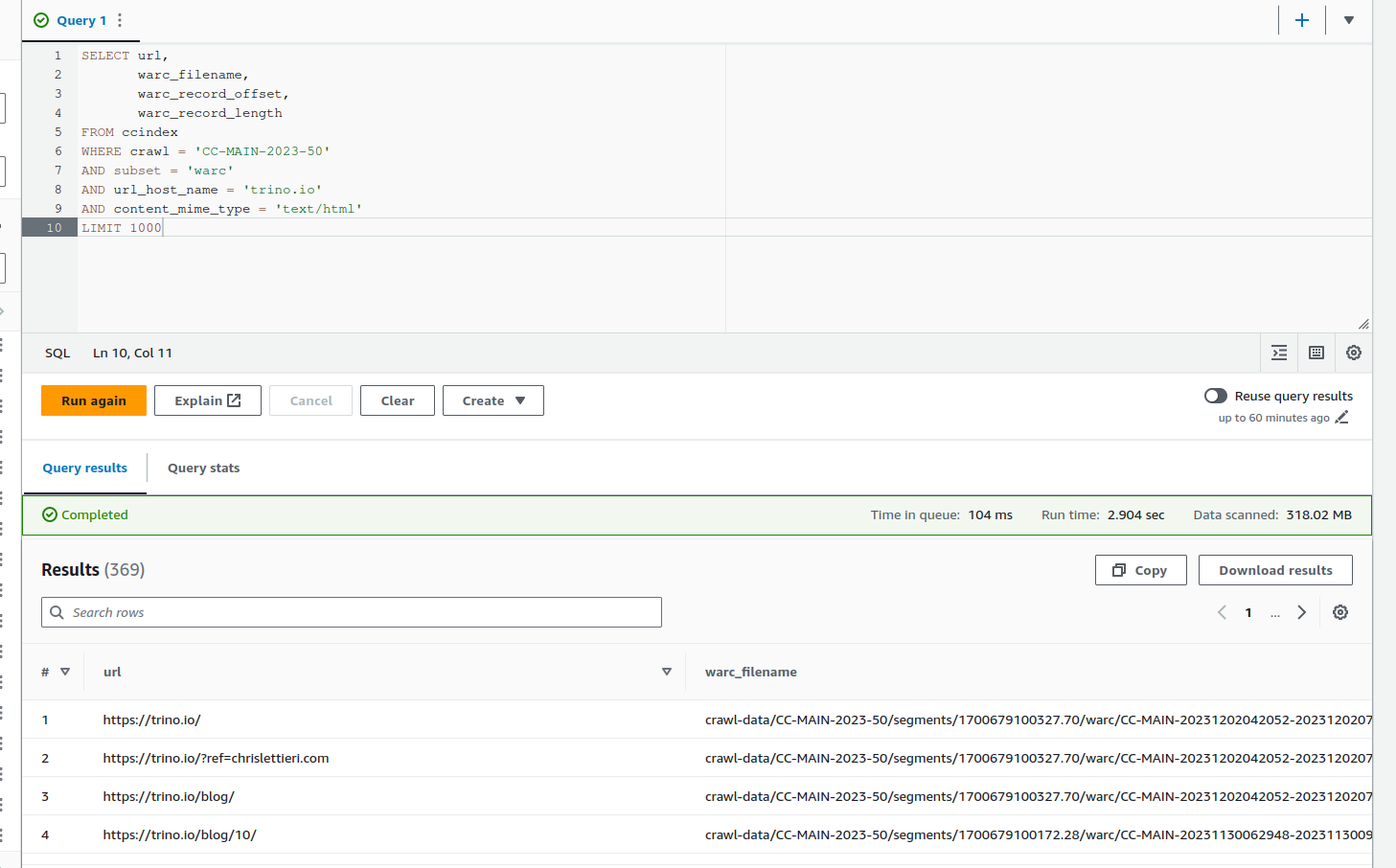
You can after export it as a CSV file and use it to download the pages.
Conclusion
Common Crawl is amazing tool to access web data without the need to crawl the web yourself. The dataset is huge and it’s perfect for bootstrapping AI projects.